
What Is Agentic Document Processing? The Complete Guide for 2026
TL;DR: Agentic Document Processing in 60 Seconds
Agentic document processing is the use of AI agents that autonomously extract, validate, classify, and act on data from documents. It goes beyond traditional optical character recognition and earlier intelligent document processing (IDP) by making multi-step decisions, flagging exceptions, and completing entire workflows without human intervention.
Where classic IDP stops at converting unstructured documents into structured output, an agentic platform reasons about that information, invokes tools, validates it against external sources, and pushes results into downstream systems. For financial institutions, the impact is measurable. FORUM Credit Union reports 99% accuracy and a 70% reduction in loan cycle time using Multimodal's AgentFlow, while Direct Mortgage Corp cut document workflow costs by 80% and accelerated time-to-decision by roughly 20x.
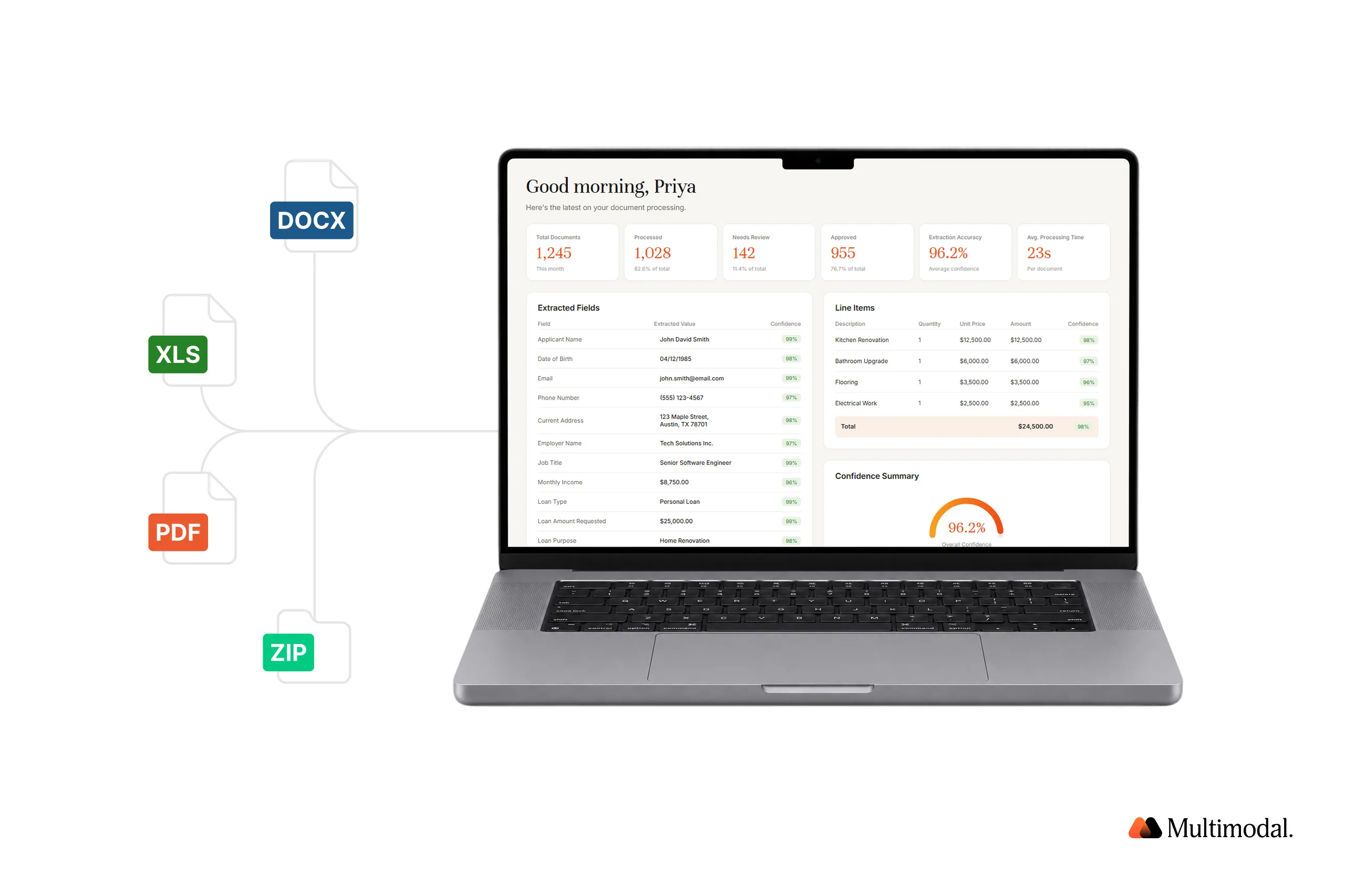
This guide explains how the agentic variant works, how it differs from legacy IDP solutions, which document types it handles, and how to evaluate an intelligent document processing platform built for regulated financial services.
Why Document-Centric Business Processes Became the Bottleneck
Every bank, credit union, insurer, and private equity firm runs on documents. Loan files, pay stubs, account statements, tax returns, insurance claims, policies, KYC files, and compliance reports flow through manual review queues, often handled by three or four analysts before a decision is made. IDC research puts 80% of enterprise data in unstructured formats, and Box estimates that 90% of all organizational data is unstructured, with a large share of financial information locked inside document images and PDFs that traditional software cannot read.
That volume has consequences. The Mortgage Bankers Association reported total loan production expenses of $12,593 per loan in Q1 2024, with labor costs typically accounting for 55% to 70% of production costs. Banks process an estimated 800 million document pages each year, and manual data entry on document-heavy fields carries an average error rate of roughly 3.6%.
On a loan file with 200+ line items, those errors compound quickly. Regulators and secondary-market investors continue to pursue lenders over post-closing defects, and the rework and repurchase costs from those defects sit squarely on the operator's balance sheet.

Artificial intelligence has promised to fix this for two decades. Early optical character recognition tools could read clean printed and handwritten text. Later, intelligent document processing software added machine learning and natural language processing to handle semi-structured documents such as invoices and remittance advice.
Those earlier IDP platforms reduced rekeying but still required humans to intervene on exceptions, write rules for every new layout, and retype extracted data into systems of record. The agentic approach changes that pattern by embedding reasoning, tool use, and workflow orchestration into the document layer itself.
This pillar covers what the agentic category is, how its architecture works, where it differs from earlier IDP, and how banks, credit unions, insurance carriers, and private equity firms are already deploying it in production.
Section 1: The Evolution of Document Handling
Document handling in financial services has moved through four distinct eras. Understanding the lineage matters because many vendors still sell technology from era two or three and label it as artificial intelligence.
Era 1: Manual Data Entry (Pre-1990s)
For most of the twentieth century, document management meant paper documents, filing cabinets, and data entry clerks. Every account statement, insurance claim, and loan application was reviewed by hand, with clerks transcribing information into mainframe systems. Data accuracy depended entirely on human attention, and human errors on complex forms routinely reached 1% to 4%.
Era 2: Optical Character Recognition (1990s–early 2000s)
The first wave of automation was optical character recognition, which converted scanned images of printed text into machine-readable characters. OCR was a breakthrough for scanned documents, but it produced a text dump with no understanding of what the characters meant. A social security number and a phone number looked the same to the machine. OCR reduced some data entry but pushed classification, validation, and interpretation downstream to humans or rigid rule engines.
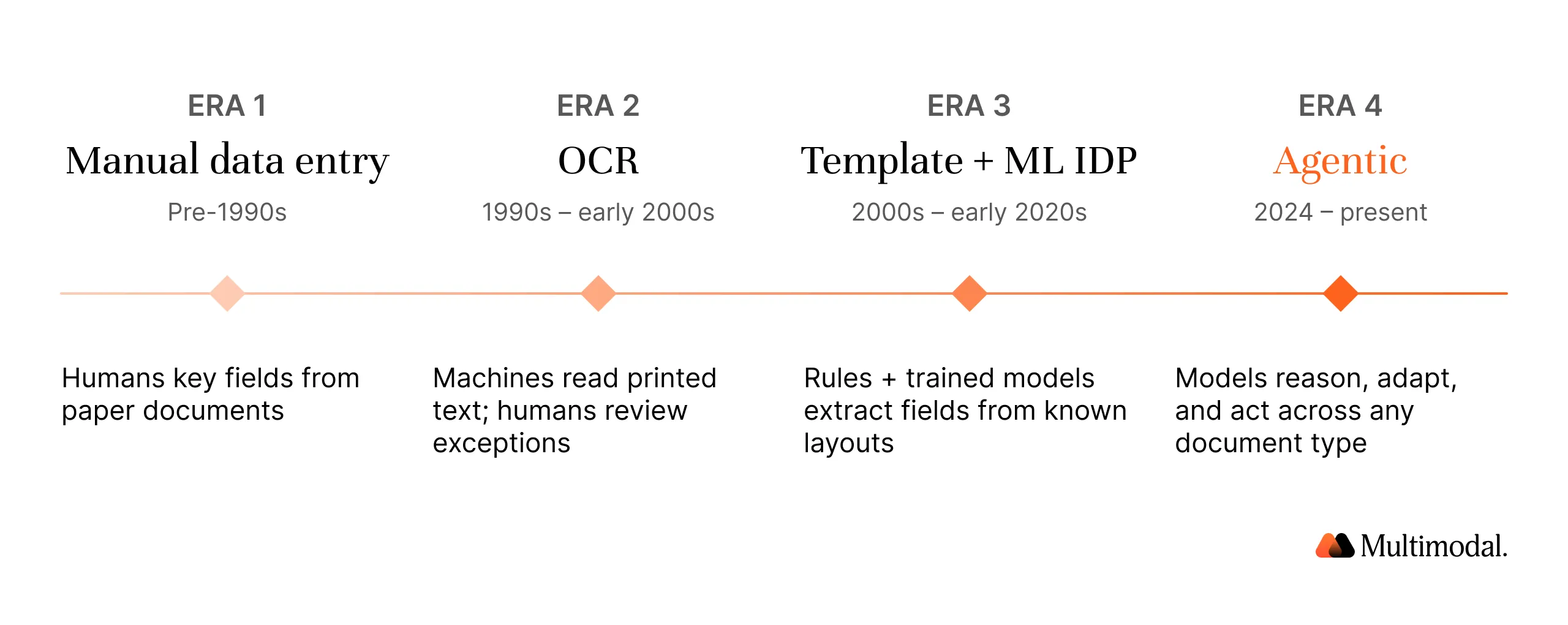
Era 3: Template-Based and Machine Learning IDP (2000s–early 2020s)
The category was then formalized around intelligent document processing. Early IDP solutions combined OCR with templates, regular expressions, and, later, machine learning models to recognize fields on invoices, purchase orders, and other form-based records.
Better platforms introduced document classification, basic data validation, and integrations with business systems. By the late 2010s, IDP was mainstream in accounts payable and claims intake, and analysts framed the category as a pillar of enterprise automation.
Traditional IDP solved the extraction problem, but it was brittle. Every new layout required new templates or retraining. Unstructured documents such as legal contracts, CIMs, and narrative underwriting memos broke the models. Exceptions still routed to humans. Gartner's own market guides described IDP as a passive extraction and classification layer rather than an autonomous decision layer.
Era 4: Agentic Document Processing (2024–Present)
The agentic era combines large language models, specialized ML, and autonomous agents that plan, reason, and act. Rather than matching a field label against a template, an agent can read a full file, understand its context, determine which data is relevant, call external tools to validate it, and trigger the next step in the workflow. The shift is from extraction to action, and from rules to reasoning.
The market reflects the shift. Gartner forecasts the intelligent document processing market to reach $2.09 billion by 2026, and broader estimates that include agentic workflows put the figure several times higher. McKinsey has written that the biggest near-term opportunity for AI in financial services lies less in exotic trading algorithms and more in the mundane but massive task of handling the billions of documents that flow through the system every year.
Multimodal sits at this frontier with AgentFlow, an agentic AI platform purpose-built for regulated financial services. Where earlier systems stopped at extracted data, AgentFlow orchestrates the process, search, decide, and create agents that carry a file from intake to final business action with full audit trails. The platform's data extraction layer runs continuously, and agents can process data from new layouts without operator intervention.
Section 2: How the Architecture Works
The architecture is best understood as a pipeline of specialized agents that hand off work to one another, with a supervisor agent coordinating the overall flow. Below is the six-step architecture that AgentFlow and other modern intelligent document processing solutions use.
Step 1: Ingestion
The pipeline begins with ingestion. Files enter from email inboxes, loan origination systems, claims portals, data rooms, core banking platforms, or partner APIs. The IDP system accepts native PDFs, spreadsheets, and even photos of forms captured on a phone, handling paper documents and digital documents in a single queue. Preprocessing handles skew correction, contrast normalization, and page splitting, so downstream agents operate on clean input regardless of source quality.
Step 2: Classification
Every incoming file is classified by type. Intelligent document classification is the first place where agentic systems pull away from legacy IDP. Traditional classifiers depend on templates or keyword rules. Agentic classifiers use vision-language models and machine learning to recognize categories based on layout, content, and context. AgentFlow can tag hundreds of document types out of the box, from W-2s and paystubs to loss runs, HUD statements, and medical records, without rebuilding templates for each new variation. Classifying documents accurately at this stage reduces exception volume at every later step.
Step 3: Extraction and Data Capture
Once classified, files move to the extraction stage. Data extraction is the stage where most of the measurable values land. Specialized agents capture data from structured, semi-structured, and unstructured inputs, handling form-based sections and narrative content within a single data processing pipeline.
One agent pulls line items from invoice data, another normalizes dates and currencies, and a third reads narrative sections with natural language processing to capture clauses and entities. The extracted data is already structured, tagged, and linked to the source location, so auditors can trace every field to its source. Automating data extraction this way turns hours of rekeying into seconds of machine work.
Unlike template-dependent IDP software, agentic extraction handles complex documents with the same pipeline it uses on simple forms. When an account statement arrives in a layout the agents have never seen, they reason about columns, dates, and running balances rather than failing the job. Capturing data from novel forms is the moment where agentic systems earn their keep. The intelligent document processing work done at this stage makes the rest of the workflow possible.
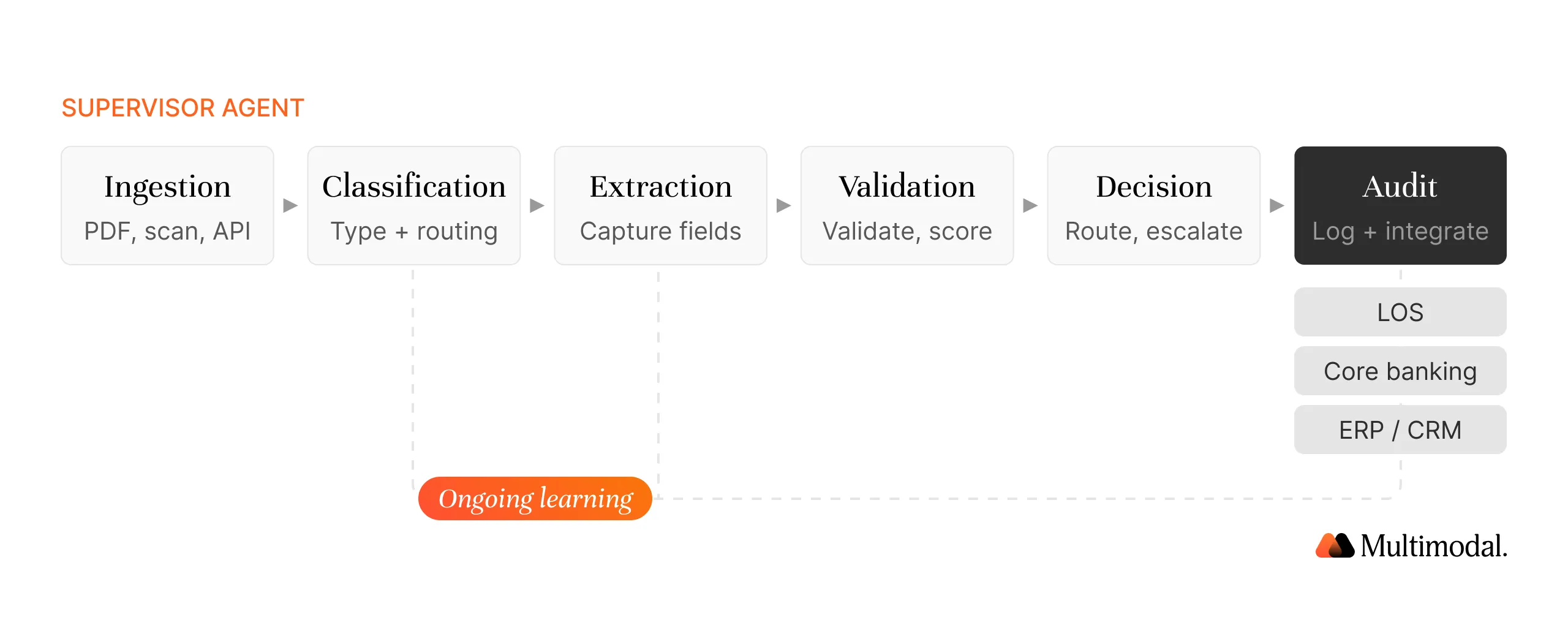
Step 4: Validation and Confidence Scoring
Extracted fields then flow into validation. Agents cross-check values against other fields in the same file, related records in the same case, and external sources. For a mortgage file, a validation agent might confirm that a paystub's year-to-date total reconciles with the W-2, that the borrower's address matches the credit report, and that the property appraisal reference matches the title.
Confidence scores are attached to every piece of extracted data. High-confidence fields move forward automatically; low-confidence fields are flagged for human review. Data validation is where accuracy becomes measurable, with leading platforms reporting straight-through rates in the 97%-99% range.
Step 5: Decision and Action
This is where the agentic approach diverges most sharply from earlier IDP. A decision agent applies the organization's policies to the validated record and takes the next action. For a consumer loan, that might mean running affordability calculations, pulling a credit bureau report, matching the file against underwriting guidelines, and either auto-approving the loan, sending it to a human reviewer, or requesting a missing item from the borrower. The approval process, historically a manual task owned by underwriters, becomes an agent-run routine with humans handling only the edge cases.
Decisions are logged with reasoning traces, policy references, and inputs, ensuring every outcome is explainable. AgentFlow's Decision AI does this for credit decisioning, claims adjudication, and due diligence, turning intelligent document processing IDP from a back-office utility into an active participant in core business operations.
Step 6: Audit, Integration, and Ongoing Learning
The final stage closes the loop. Results are written into systems of record: loan origination platforms, policy administration systems, core banking, CRMs, and ERPs. Every action creates an audit record. Compliance teams get a replayable trail showing what was read, what was decided, and why.
Continuous learning is the other half of this step. When a human corrects an exception, the correction feeds back into the machine learning models. Over time, the platform can autonomously process documents at higher volumes, pushing further processing into the automated path and leaving only the hardest cases for people. This flywheel is what separates an agentic process automation system from a one-shot extraction tool.
Section 3: Agentic vs Traditional IDP: The Key Differences
The single most cited question in buyer conversations today is how the agentic approach differs from classic intelligent document processing. The table below captures the operational differences that matter in regulated financial services.
Comparison: Traditional IDP vs Agentic IDP
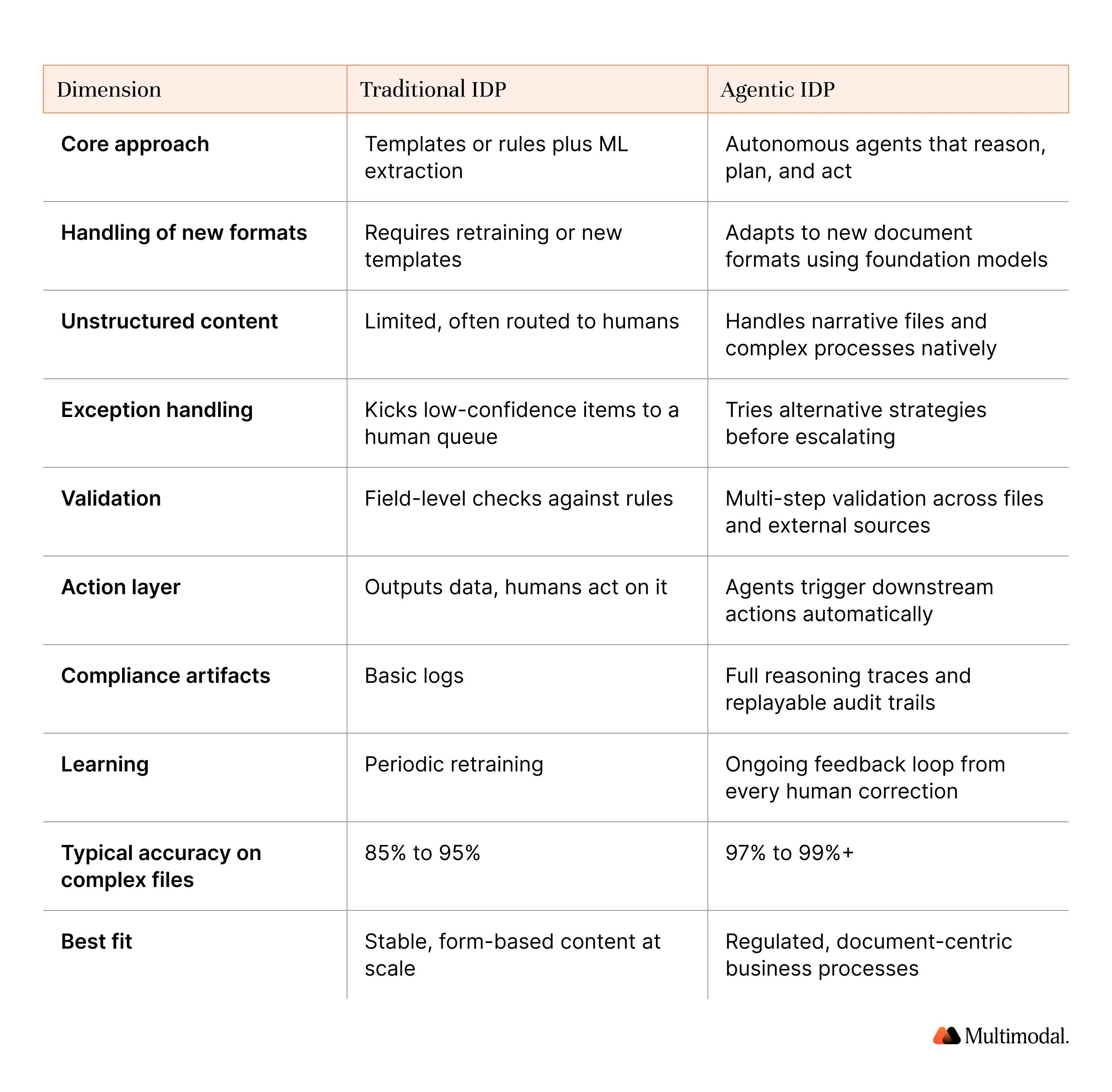
Traditional IDP still works well when the layouts are narrow, stable, and predictable. Invoice processing at a high-volume shared services center is a reasonable fit, as long as vendors rarely change their forms. The moment the workflow includes scanned documents, narrative text, multiple documents per case, or the need to validate data against external sources, the legacy model breaks down.
Agentic platforms are designed for exactly those document-centric business processes. They handle novel layouts, read context, and integrate with the systems of record that actually own the work. This is how leading IDP solutions now automate complete workflows end-to-end, rather than handing analysts a cleaner spreadsheet. The intelligent document processing work that used to require a team of offshore clerks now runs on a pipeline of agents.
Section 4: Use Cases by Industry
The pattern shows up in different shapes across industries. Below are the most common deployments Multimodal sees today, each with the relevant document categories, workflows, and proof points.
Lending and Credit Unions
Consumer and commercial lending is the most document-heavy process in banking. A single auto loan package can include 15 to 60 pages of applications, pay stubs, tax returns, bank statements, titles, insurance binders, and dealer invoices. Underwriters are expected to read, verify, and decide on all of it in hours.
FORUM Credit Union deployed Multimodal's AgentFlow to automate classification and data extraction across consumer loan packages. Accuracy exceeded 99% across 62 document packages, each ranging from 15 to 61 pages, and cycle time dropped by 70%. Decision AI then handled credit calculations and payout values, creating explainable, regulator-ready decisions that flowed straight into Temenos. FORUM's team no longer spends its day on repetitive tasks like sorting and rekeying; it focuses on exceptions and member relationships.
.svg)
Direct Mortgage Corp reports a similar pattern. By automating data extraction from pay stubs, financial documents, tax forms, and more than 200 other categories, Direct Mortgage cut document workflow costs by 80% and accelerated time-to-decision by roughly 20x compared to manual underwriting. The IDP system there now covers most of the document data that underwriters used to handle by hand, and the volume of document data each analyst touches has dropped by roughly the same share.
Lending-specific applications include:
- Loan origination for consumer, auto, mortgage, small business, and SBA loans
- Loan servicing, including payoff requests, escrow analysis, and modifications
- Credit decisioning and underwriting, with data capture from income and asset records
- KYC and onboarding, where agents read identity records and proofs of address in parallel
- Fraud detection across loan and payment workflows
Insurance
Insurance is the other document-centric industry in which agentic systems are changing the operating model. Claims intake, policy issuance, underwriting, and subrogation all turn on the ability to analyze document content across insurance claims, policies, medical records, loss runs, and ACORD forms.
A First Notice of Loss file can include photos, police reports, adjuster notes, and prior history. An agentic platform classifies every record, extracts relevant data, validates against policy coverages, and either adjudicates the claim or routes it to the right adjuster. Commercial lines underwriting, long dominated by manual review of loss runs and schedules, is collapsing into minutes.
Peer-reviewed research on agentic AI for commercial insurance underwriting, published on arXiv in early 2026, reports decision accuracy rising from 93% to 97% on mid-complexity cases when an adversarial critic agent is layered on top of the primary agent, with substantially faster quote cycle times than manual review.
Common insurance workflows include FNOL intake and triage, claims adjudication, policy issuance and renewal, subrogation, and compliance reporting.

Private Equity and M&A
Private equity firms live in virtual data rooms. Due diligence on a mid-market deal can involve thousands of business documents: CIMs, financial statements, customer contracts, employee agreements, legal documents, and environmental reports. Analysts used to spend weeks reading and tagging.
Agentic systems collapse that timeline. An M&A playbook can process data room documents at scale, extract key terms from contracts, summarize statements, cross-reference transactional data across files, and surface risks in hours rather than weeks. The same pattern applies to portfolio monitoring, where agents parse quarterly reporting packages and push structured data into LP reporting tools.
Accounts Payable and Finance Operations
Invoice processing remains a high-volume application. AP agents ingest invoices, POs, GRNs, and receipts, validate line items against purchase orders, apply tax rules, and post to the ERP. Finance operations teams have moved from an AP clerk model to a controls-and-exceptions model, with agents handling 70% to 90% of items with no human touch. The shift is a clear example of how modern IDP can automate business processes rather than just speed up parts of them, letting the platform process data in bulk and escalate only true exceptions.
Healthcare Finance and Claims
Healthcare revenue cycle and patient financing workflows depend on accurately reading patient records, EOBs, and insurance records. Sensitive data handling, including PHI, requires purpose-built governance. Agentic systems with proper SOC 2 and HIPAA controls are replacing offshore data entry and legacy rule engines, with measurable gains in denial management and time to collect.
Section 5: Accuracy, Compliance, and the 99% Threshold
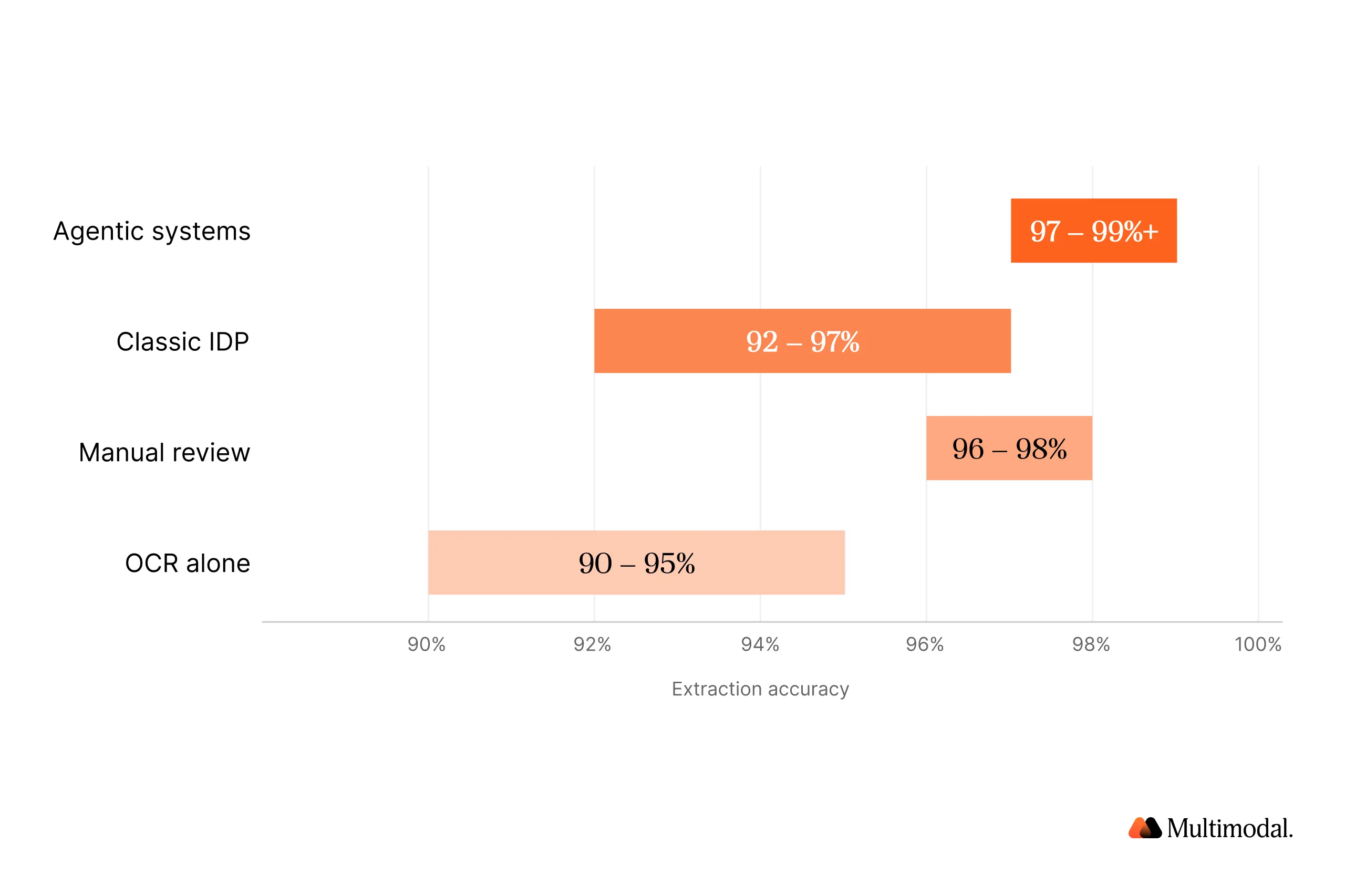
Accuracy is the number that sells an IDP system to operators and breaks the project if it is wrong. In regulated financial services, the gap between 95% and 99% is the difference between a working platform and a compliance liability.
A rough accuracy ladder tracks the evolution of the category:
- Manual review: 96% to 98% field accuracy on typical loan files, with 1% to 4% human errors on complex forms
- OCR alone: 90% to 95% character accuracy on clean print, much lower on faded scans and smudged characters
- Classic IDP: 92% to 97% on form-based content with consistent layouts, lower on unstructured inputs
- Agentic systems: 97% to 99%+ on mixed content with ongoing retraining
Why does the last point matter so much? Because in a lending operation, a 2% error rate compounds. On a 200-field loan file, a 2% field-level error rate means roughly four errors per file. Multiply by 10,000 loans per year, and you have 40,000 defects, many of which will only surface in QC or regulatory exams.
One mortgage lender has publicly cited a 61% reduction in defect escape rates after moving to a machine-learning-based extraction platform, with further gains expected once agentic validation is layered on top. Modern platforms improve accuracy every quarter as learning loops retrain models on real corrections, which also helps improve accuracy across the long tail of novel layouts.
Compliance requirements in 2026 raise the stakes further. NCUA's 2026 supervisory priorities emphasize loan quality, interest rate and liquidity risk, fraud prevention in payment systems, and BSA/AML compliance. The NCUA's AI Resource Hub now sets expectations for how credit unions govern AI and third-party risk.
Federal bank regulators expect explainable decisions and replayable audit trails. The CFPB continues to pursue improvements in the quality of adverse action notices in credit decisions. SOC 2 Type II attestation has become table stakes for vendors that handle sensitive data.
A well-designed IDP system meets these requirements by default. AgentFlow, for example, ships with SOC 2 Type II, explainable decision logs, field-level source traceability, role-based access control, and PII and PHI redaction. Compliance is part of the architecture.
Accuracy also depends on how the platform handles exceptions. Agentic systems do not pretend that every field will be perfect. They manage uncertainty by attaching confidence scores, trying alternative extraction strategies, and escalating only when necessary. Over time, continuous learning from every correction closes the gap, minimizing errors and raising throughput across the long tail.
Section 6: How to Evaluate an Intelligent Document Processing Platform
Choosing an intelligent document processing platform is a multi-year decision. The right platform automates end-to-end; the wrong one becomes another point tool that creates new handoffs. Use the ten criteria below as a scoring framework for comparing IDP solutions.
1. Workflow Coverage
Does the platform automate the full document-centric business process, not just extraction? Look for end-to-end orchestration from ingestion to decision to system-of-record update. Tools that stop at captured data leave most of the value on the table.
2. Accuracy on Your Document Types
Request a proof of concept using your actual files, not generic samples. An agentic platform should demonstrate 99%+ accuracy on the specific scans and edge cases that define your workload. Ask how accuracy is measured, at the field level or the document level, and confirm which metric the vendor reports.
3. Handling of Unstructured and Complex Content
Unstructured documents such as narrative underwriting memos, legal documents, and faded bank statements reveal which platforms are truly agentic and which still depend on templates. Test the hardest content you have. Also, ask how the platform handles subsequent processing steps such as reconciliation, exception routing, and downstream enrichment.
4. Validation and Decision Capabilities
Pure data processing is commoditized. The real question is whether the platform can validate data, apply business rules, and make explainable decisions. Ask how decisions are logged, versioned, and audited.
5. Compliance and Governance
For banks, credit unions, and insurers, compliance is the gate. Confirm SOC 2 Type II, data residency controls, PII and PHI handling, explainability, and role-based access. If the vendor cannot show audit artifacts, the platform is not production-ready for regulated industries.
6. Integration with Your Systems of Record
An agentic platform only pays off when it writes back into core systems. Check for native integrations or low-effort connectors to loan origination, policy administration, core banking, ERP, and CRM platforms, plus the document management layer that stores the source files.
7. Time to Production
Time to first workflow live is a proxy for vendor maturity. Multimodal ships AgentFlow Playbooks for common workflows, including credit decisioning, KYC, AML, and FNOL, enabling production go-lives in weeks rather than quarters.
8. Ongoing Learning Loop
Ask how the platform improves over time. A system that does not learn from corrections will plateau. Look for built-in feedback so every human review trains the underlying machine learning models.
9. Security and Data Handling
Workloads include highly sensitive data, such as patient records, financial documents, KYC files, and insurance claims. Confirm encryption at rest and in transit, tenant isolation, retention controls, and the option to run in customer-controlled environments.
10. Economic Model and Total Cost of Ownership
Pricing models vary: per page, per document, per decision, per workflow. Model the total cost, including integration, training, ongoing ops, and the internal team needed to maintain the platform. Forward-deployed engineering support from the vendor typically shortens the payback period.
Gated Resource: Download the 2026 Intelligent Document Processing Buyer's Guide, which includes scoring templates, RFP questions, and an ROI model calibrated for lending and insurance.
Section 7: Multimodal's Approach with AgentFlow
Multimodal built AgentFlow as the agentic AI platform for regulated financial services. The platform combines four agent families: Document AI for classification and data extraction, Decision AI for policy-driven decisions, Conversational AI for querying knowledge bases and conversational interfaces, and Report AI for generating compliance artifacts. Together, they deliver true intelligent document processing IDP capabilities that span intake through action.
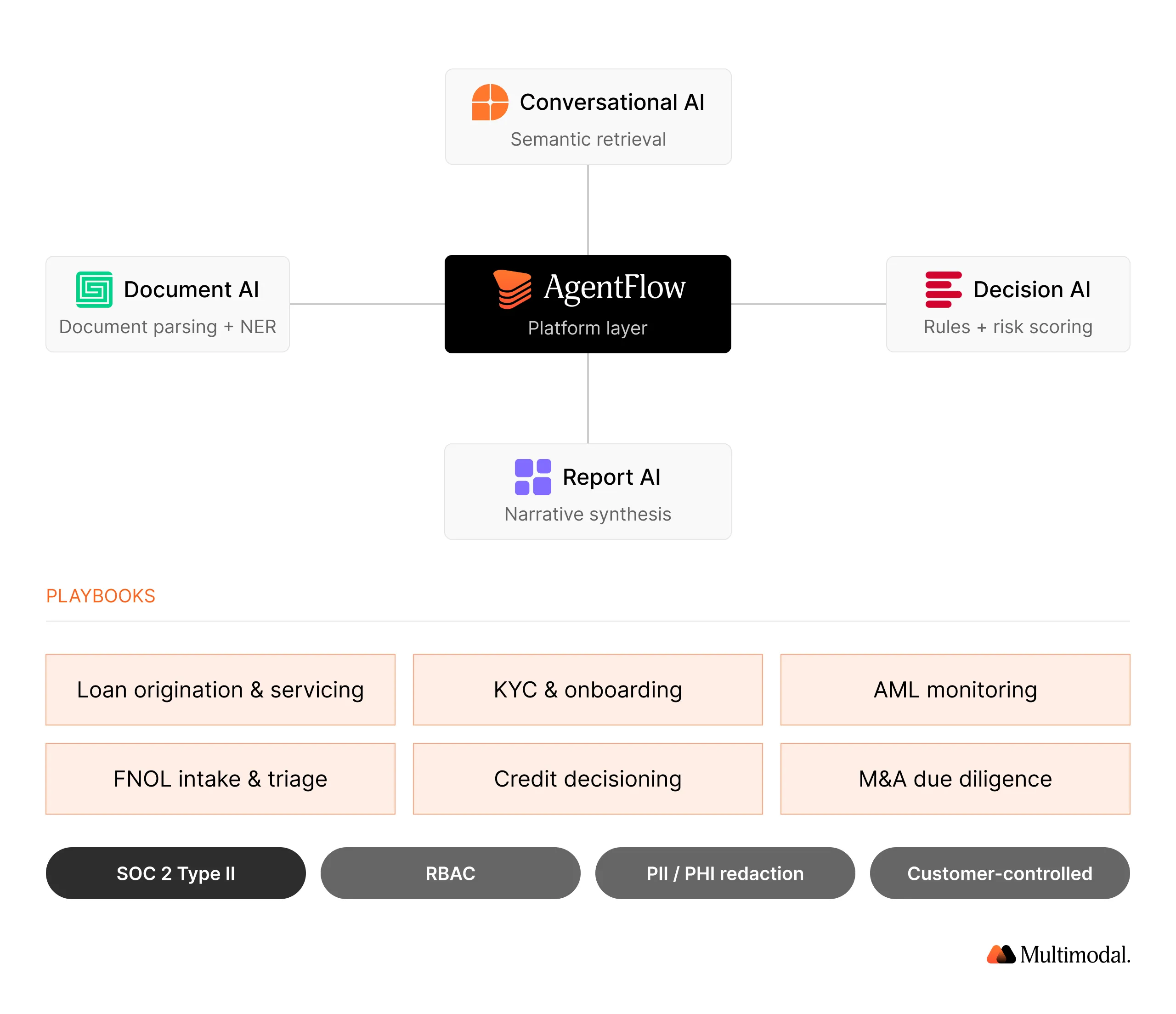
AgentFlow ships with pre-built Playbooks for the most common financial services workflows: Loan Origination and Servicing, KYC and Onboarding, AML Monitoring, FNOL Intake and Triage, Credit Decisioning and Underwriting, and M&A Due Diligence. Each Playbook is a production-grade template that operators can configure, test, and deploy in weeks.
Governance is built in. Every decision carries explainability artifacts. Every piece of data extracted is traceable to its source. SOC 2 Type II is standard. Role-based access, PII redaction, and deployment in customer-controlled environments are available where required.
Results show up in numbers operators care about. FORUM Credit Union reports 99% accuracy and 70% faster cycle time. Direct Mortgage Corp reports 80% reduction in document workflow costs. These are audited customer outcomes, not lab benchmarks, and they are published in Multimodal's customer stories.
.svg)
FAQ: Agentic IDP
Optical character recognition converts document images and scans of printed and handwritten text into machine-readable characters. It does not understand the meaning. Intelligent document processing adds classification, machine learning, natural language processing, data validation, and integrations with downstream systems to turn recognized text into structured data that operational platforms can consume. Modern IDP is often agentic, meaning the agents reason about captured fields and take action on them.
No. IDP is a specific category focused on reading and understanding documents. Agentic AI is a broader pattern where software agents plan, decide, and act autonomously across business workflows. The agentic variant of intelligent document processing IDP is the intersection. It applies agentic AI to the document layer, turning IDP from a passive extraction utility into an active participant that runs complete business operations.
Accuracy depends on content type and platform. Legacy OCR typically runs at 90% to 95% character accuracy on clean print. Traditional ML extraction averages 92% to 97% on form-based content. Agentic platforms regularly achieve 97% to 99%+ on mixed workloads, with a learning loop that keeps improving the long tail. Multimodal customers such as FORUM Credit Union have reported 99% accuracy on production loan files.
Modern intelligent document processing software handles structured documents such as tax forms and applications, semi-structured files such as invoices and statements, and unstructured documents such as contracts and narrative memos. Common categories include paystubs, W-2s, tax returns, invoices, purchase orders, legal documents, insurance policies, loss runs, medical records, patient records, KYC files, and identity records. Agentic systems also process multiple documents as a single case rather than one file at a time.
With a traditional IDP platform, implementations often run six to twelve months because every layout requires templates and training. Agentic intelligent document processing solutions built around foundation models compress the timeline. AgentFlow Playbooks regularly hit production in under 90 days for common workflows. Custom builds with deeper integration into core systems can take longer, but the gating factor is usually integration and change management, not the AI itself.
Robotic process automation excels at moving data between applications using deterministic rules. The agentic variant handles the upstream work of turning unstructured data into structured output and making decisions about it. The two are complementary. Many enterprises are replacing brittle RPA bots that depended on templates with agentic systems, while keeping robotic process automation where simple system-to-system moves are all that is required.
Yes, when the platform is purpose-built for the use case. Look for SOC 2 Type II attestation, explainable decisions, field-level source traceability, role-based access, PII and PHI handling, data residency controls, and the option to deploy in customer-controlled environments. AgentFlow meets these requirements by default and supports NCUA, OCC, FDIC, and state regulator expectations for AI governance in financial services.
Start where manual data entry, human errors, and repetitive tasks create the highest cost. The three patterns Multimodal sees most often are consumer and mortgage loan origination, insurance claims intake and adjudication, and AP automation. Each one involves high volume, well-defined policy, and measurable ROI on cycle time and accuracy.
Every time a human reviewer corrects a field or overrides a decision, the platform records the correction as training data. The machine learning models are periodically retrained, and agents adjust their strategies. Over months, the system handles a wider variety of content with less human touch, driving accuracy and throughput higher.
Agentic platforms integrate into existing workflows rather than replacing them wholesale. AgentFlow connects to loan origination systems, claims platforms, core banking, ERP, and data warehouses through native integrations and APIs. Extraction happens upstream, and validated business data flows into the core systems that operators already use, enabling businesses to automate without ripping out infrastructure.
See AgentFlow in Action
.svg)
.svg)