Automate end-to-end insurance workflows security for 4x faster turnaround.
The AI platform purpose-built for financial services.
Processes unstructured data for RAG architectures and downstream GenAI applications.
Trained on your schema to extract data and organize documents.
Makes business decisions from your data to minimize risk and maximize ROI.
Turns raw data into insights for employees and customers.
Uses unstructured data to provide client and employee support.
Generates ready-to-publish content, from reports to blog posts.
Company news and guides on industry-specific AI.
Educational content series led by our founder.
Live discussions and tips on enterprise AI.
Case studies from previous and current customers.
Learn more about our mission.
Explore open positions.
See how we handle your data.
Explore our industry recognition.
News and press coverage.












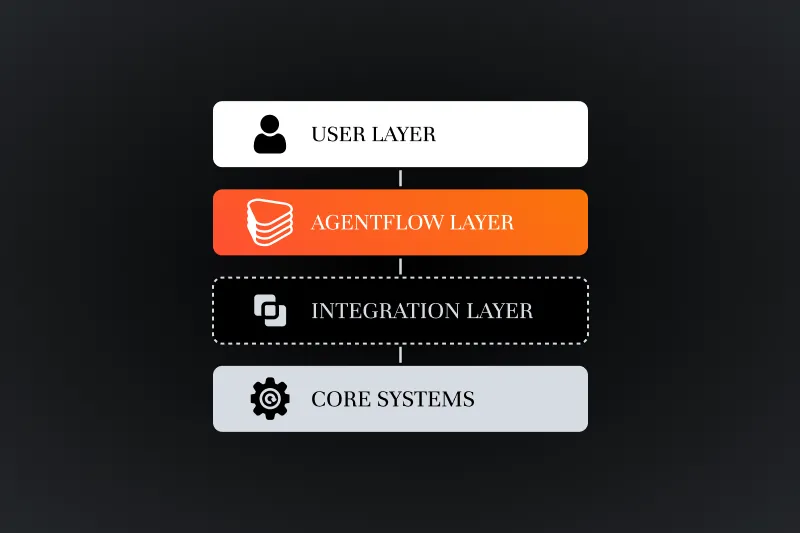
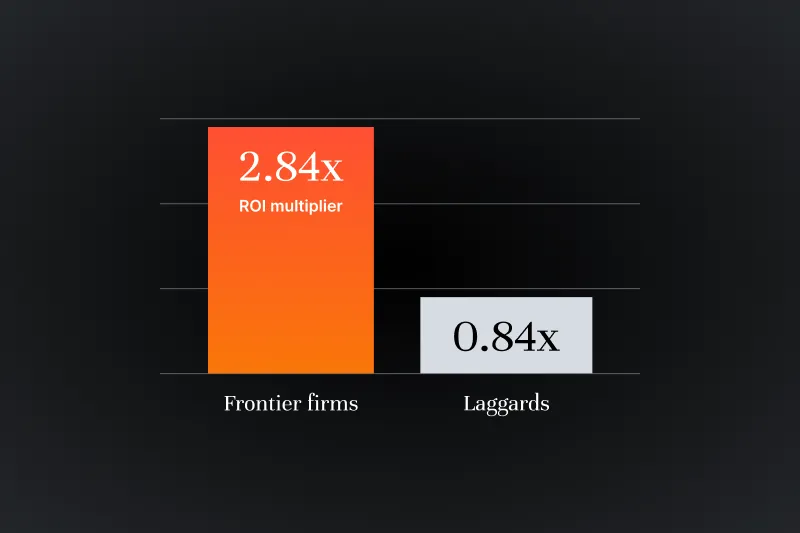
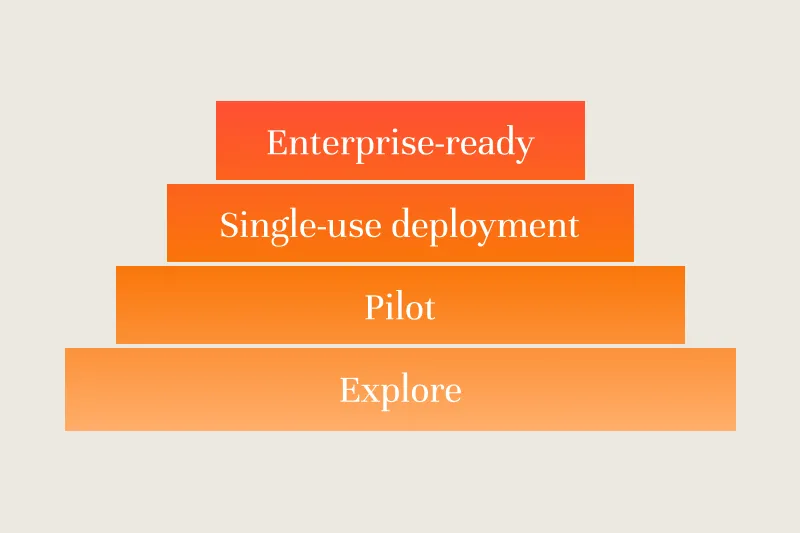
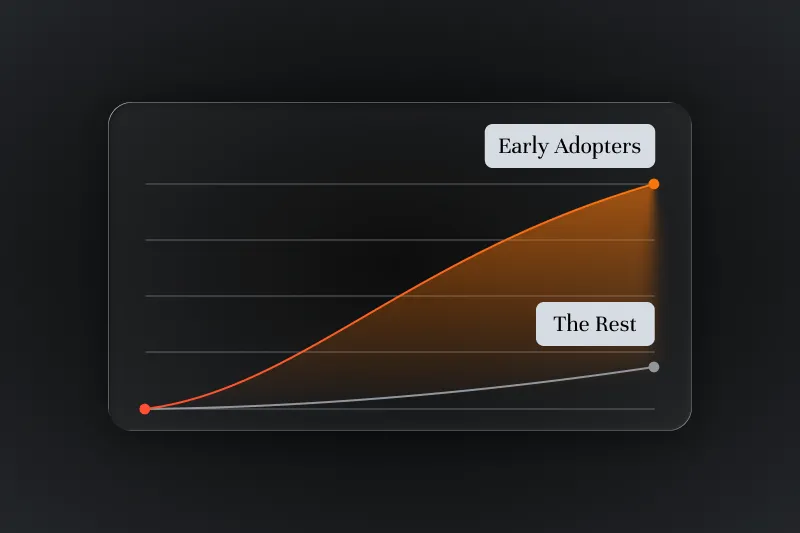
.webp)





























-A-CIO-Playbook.webp)



.webp)


































.avif)



.webp)



.webp)
.webp)

.webp)

.webp)

.webp)

.png)













.webp)
.webp)



.webp)


























%20(2).webp)












%2520October%25202024-3.png)




















































.avif)
.avif)
.webp)
%20(Blog%20Banner).avif)
.webp)

.webp)
.webp)
.webp)
.webp)




.webp)
.webp)
.webp)
.webp)
.webp)
.webp)
.webp)