Data extraction from unstructured documents is a complex task for many businesses. Extracting structured, actionable data from PDFs, reports, and scanned documents is hard, especially when content includes text, tables, charts, and images.
General-purpose, consumer-grade AI tools aren’t built to handle that complexity.
Tools like Anthropic Claude 4 (Opus), Google Gemini 2.5 Pro, and OpenAI o3 have transformed natural language processing (NLP) across many use cases. But their performance struggles when applied to the specialized demands of enterprise data extraction.
Get 1% smarter about AI in financial services every week.
Receive weekly micro lessons on agentic AI, our company updates, and tips from our team right in your inbox. Unsubscribe anytime.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
In this analysis, we wanted to test whether Unstructured AI, a purpose-built AI agent designed for data extraction from unstructured documents, outperforms these widely used consumer tools.
Our goal was to determine if specialized AI, fine-tuned for document processing, could deliver more reliable, accurate, and efficient results than generalized models.
This report provides key findings, methodology, results, and a clear conclusion on why Unstructured AI is the most effectivesolution for enterprises that need to extract valuable insights from unstructured data at scale.
Key Findings
Unstructured AI outperforms generic models even without a feedback loop: The version of Unstructured AI tested here does not incorporate Multimodal’s proprietary feedback loop. This feedback loop further improves Unstructured AI performance, enabling ~99% precision and ~95% recall.
Without a feedback loop, Unstructured AI achieves 97% precision and 86% recall, higher than the best reasoning models from OpenAI, Google, and Anthropic.
These results establish Unstructured AI as the best-in-class solution for data extraction from finance-specific documents.
The report will be updated quarterly to ensure regular product testing and improvement.
Methodology
The benchmark used a single financial document to ensure consistency across models:
Test artifact: “Ranger Summary Fact Sheet” (a 6-page financial teaser)
Content: Investment overview, with text, tables, and charts
Prompt: “Extract information from this attached document into a clean, organized JSON. Extract info from tables and charts, too.”
Each model received the same PDF and prompt. Outputs were compared against a ground-truth schema. The resulting JSON outputs were saved as separate files, one per model, for later evaluation.
Evaluations measured:
Precision (%): Correct fields ÷ Total extracted fields
Recall (%): Correct fields ÷ Total required fields
Qualitative notes: Formatting issues, omissions, symbol handling
We then tested AgentFlow Unstructured AI (internal pipeline) against the following models:
Anthropic Claude 4 (Opus) Reasoning
Google Gemini 2.5 Pro (reasoning)
OpenAI o3 (OpenAI’s reasoning model)
Evaluation was performed on July 24, 2025, with multiple independent passes across DeepSeek R1, Perplexity (Grok 4), and Anthropic Claude Opus 4.
Results
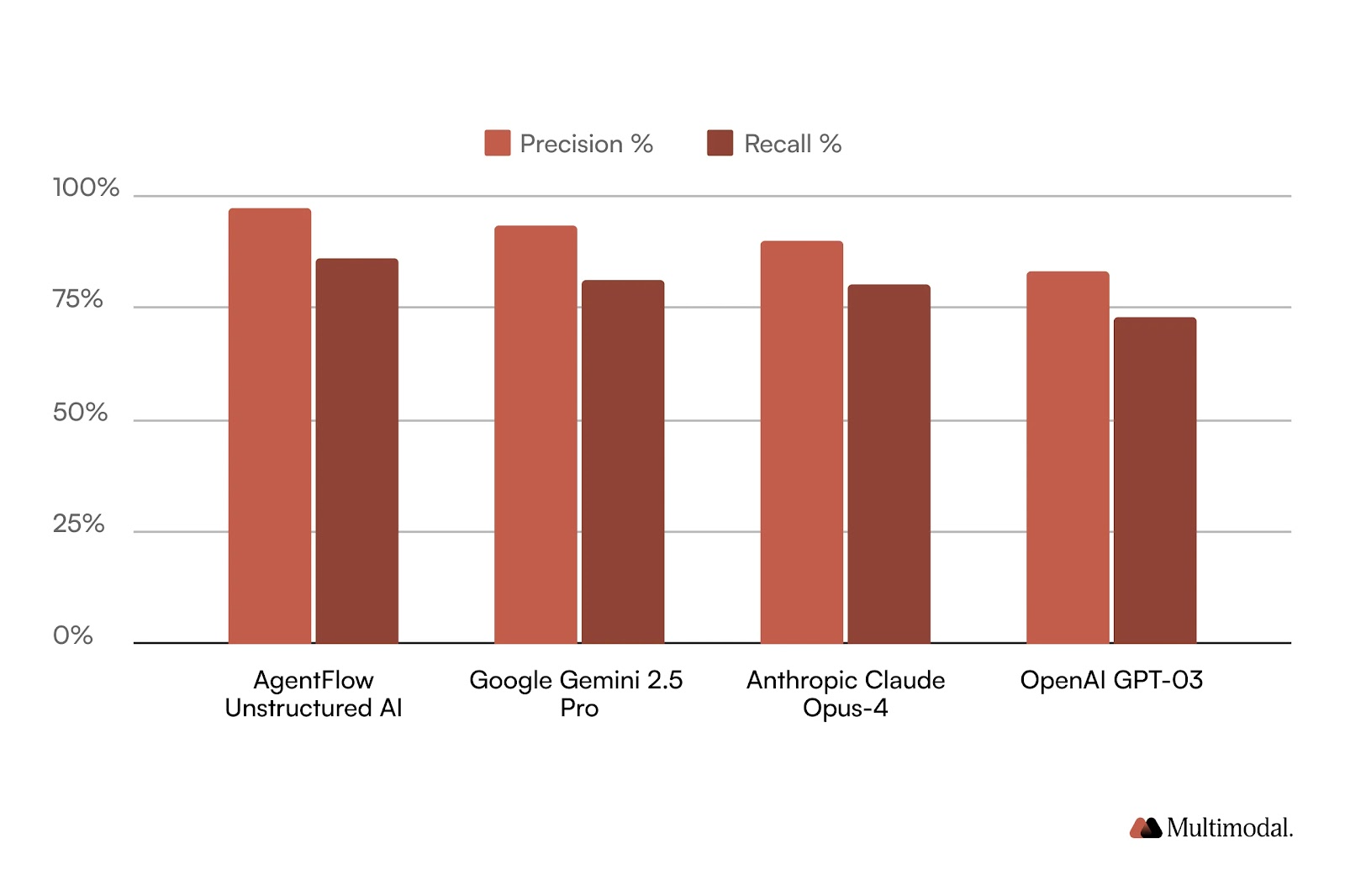
The benchmark showed that Unstructured AI outperformed all tested models in both accuracy and completeness.
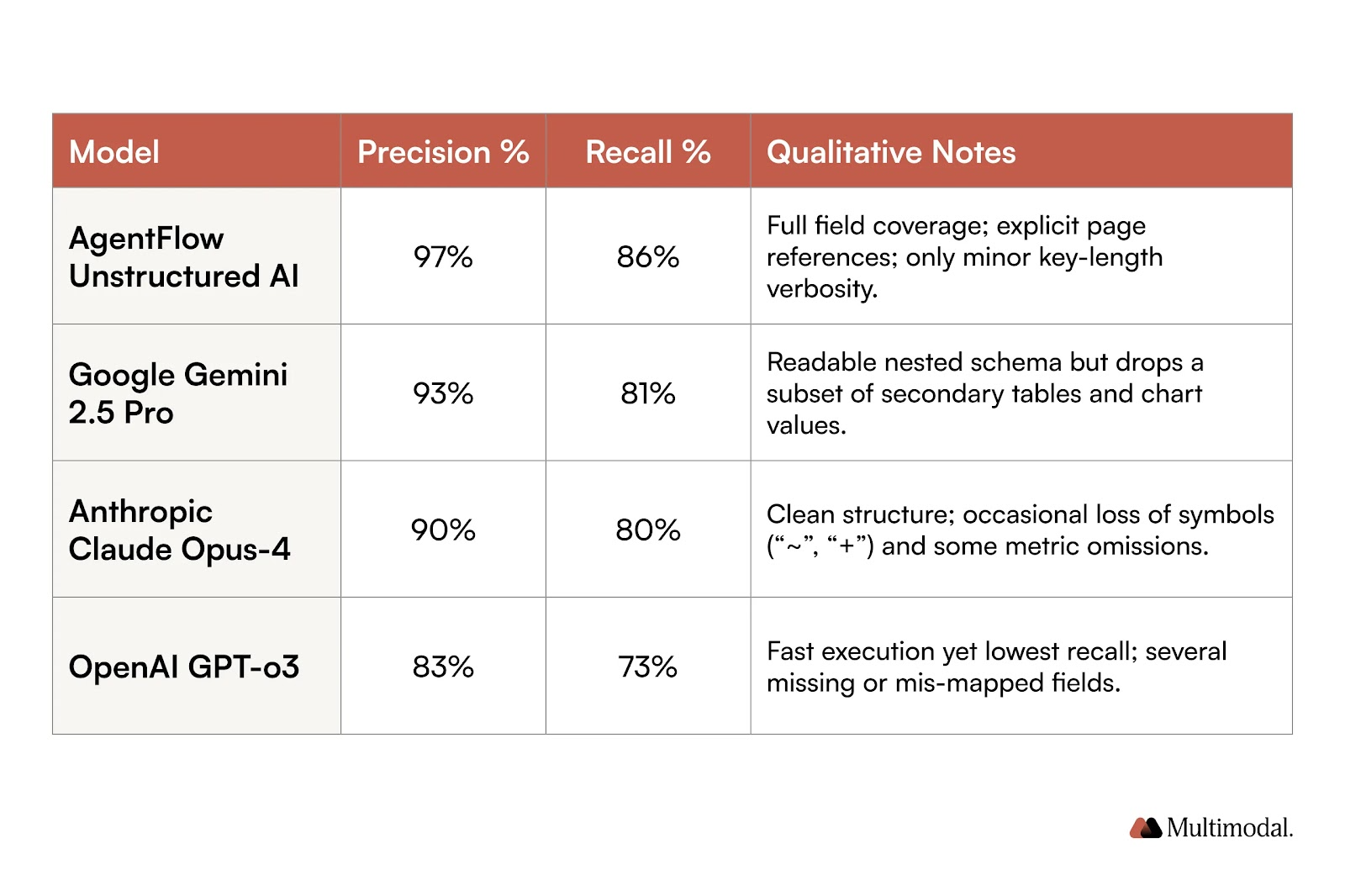
Unstructured AI achieved 97% precision and 86% recall, the highest scores in the test. It provided full field coverage and page-level references, with only minor verbosity in key naming.
Google Gemini 2.5 Pro ranked second with 93% precision and 81% recall. Its JSON was readable and well-structured, but omitted some secondary tables and chart values, reducing completeness.
Anthropic Claude Opus 4 scored 90% precision and 80% recall. Its outputs were clean and consistent, but it often dropped key symbols like “~” or “+” and missed some metrics.
OpenAI o3 scored 83% precision and 73% recall. While it processed the document quickly, it produced the lowest recall, with several missing or mis-mapped fields.
These results confirm that Unstructured AI sets the benchmark for precision and recall in financial document extraction, minimizing the need for manual correction and reducing downstream remediation.
The overall performance proved that while Google Gemini 2.5 Pro, Anthropic Claude Opus 4, and OpenAI o3 are powerful in open-ended tasks, they cannot match Unstructured AI’s tailored ability to handle enterprise-specific document extraction needs.
Conclusion
Unstructured AI is the clear winner for enterprise-grade data extraction from unstructured documents. Purpose-built for business-critical workflows, it handles complex financial, legal, and insurance content, delivers confidence-scored outputs, and integrates securely into enterprise environments.
Unstructured AI minimizes risks, reduces costs, and accelerates insights, enabling teams to turn unstructured data into structured, actionable intelligence at scale.
Gemini 2.5 Pro and Claude Opus-4 remain viable for less stringent use cases but typically require post-processing to fix missing content, while o3 is best suited to rapid prototyping rather than production workloads.
We’ll revisit the benchmark quarterly to track performance, guide improvements, and validate Unstructured AI against leading models.
Want to see why Book a Demo for Unstructured AI is a better choice?
Discover how Unstructured AI can transform your document data extraction processes. Book a demo today and see firsthand how our specialized AI solution can help your organization automate and streamline complex workflows, improve accuracy, and reduce costs.
Appendix
Appendix A – Evaluation Prompt
Role
You are a data-quality evaluator reviewing four JSON files produced by a PDF-extraction pipeline.
Inputs
The source PDF (ground-truth content).
Four JSON extraction outputs (use the name of the documents).
A list of required key-value pairs that should be captured from the PDF (ground-truth schema).
Tasks
Field-level comparison: For every required key, compare each JSON value with the corresponding value in the PDF. Mark each key as Correct or Incorrect for every JSON file.
Metrics:
Precision % = (Correct keys ÷ Total keys extracted) × 100 for each JSON.
Recall % = (Correct keys ÷ Total required keys) × 100 for each JSON.
Qualitative review: Note any systematic errors (e.g., wrong date formats, truncated text, missing tables). Highlight relative strengths and weaknesses of each JSON (clarity, completeness, formatting consistency).
Output
Present a summary table: JSON file | Precision % | Recall % | Key error themes. Provide a concise narrative comparing overall quality across the four JSON outputs and recommending the best performer.
Appendix B – Run Date & Environment
Date: 24 July 2025
Platforms:
Perplexity (Grok 4, July 2025 release)
Anthropic Claude Opus 4 (July 2025 snapshot)
DeepSeek R1 Thanking (July 2025 snapshot)
See AgentFlow Live
Book a demo to see how AgentFlow streamlines real-world finance workflows in real time.

.svg)
.svg)
.avif)
.png)

.png)